@inproceedings{ha2017hypernetworks,
title={HyperNetworks},
author={Ha, David and Dai, Andrew M and Le, Quoc V},
booktitle={International Conference on Learning Representations},
year={2017}
}Abstract
이 연구는 하이퍼네트워크를 탐구합니다. 하이퍼네트워크는 한 네트워크를 사용하여 다른 네트워크의 가중치를 생성하는 방식입니다.
하이퍼네트워크는 자연에서 발견되는 것과 유사한 추상화를 제공합니다: 유전형질(하이퍼네트워크)과 표현형(주 네트워크) 간의 관계입니다.
진화 알고리즘의 HyperNEAT과 유사하지만, 본 연구의 하이퍼네트워크는 역전파(backpropagation)로 End-to-End 학습되므로 일반적으로 더 빠릅니다.
본 연구의 초점은 하이퍼네트워크를 심층 합성곱 신경망과 장기 순환 신경망에 유용하게 만드는 것입니다. 여기서 하이퍼네트워크는 계층 간 가중치 공유의 완화된 형태로 볼 수 있습니다. 주요 결과는 하이퍼네트워크가 LSTM의 비공유 가중치를 생성할 수 있으며, 문자 수준의 언어 모델링, 필기 생성, 신경 기계 번역을 포함한 다양한 시퀀스 모델링 작업에서 최첨단에 가까운 성능을 달성할 수 있다는 것입니다.
이는 순환 신경망의 가중치 공유 패러다임에 도전합니다. 또한 결과는 합성곱 신경망에 적용된 하이퍼네트워크가 최첨단 기준 모델과 비교하여 이미지 인식 작업에서 뛰어난 결과를 달성하면서도 학습 가능한 매개변수가 더 적음을 보여줍니다.
Introduction
본 연구에서는 작은 네트워크(하이퍼네트워크라고 불림)를 사용하여 더 큰 네트워크(주 네트워크라고 불림)의 가중치를 생성하는 방식을 고려합니다. 주 네트워크의 동작은 일반적인 신경망과 동일합니다: 원시 입력을 원하는 목표로 매핑하도록 학습합니다. 반면 하이퍼네트워크는 가중치 구조에 대한 정보를 포함하는 입력 세트를 받아서 해당 계층의 가중치를 생성합니다(그림 1 참조).
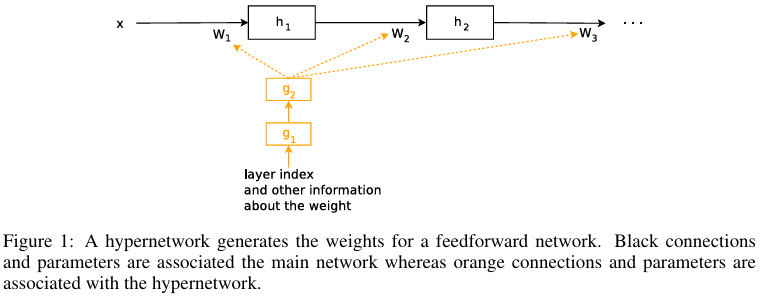
HyperNEAT은 하이퍼네트워크의 예이며, 여기서 입력은 주 네트워크의 각 가중치에 대한 가상 좌표 집합입니다. 본 연구에서는 입력이 주어진 계층의 전체 가중치를 설명하는 임베딩 벡터인 더 강력한 방식에 중점을 둡니다. 우리의 임베딩 벡터는 고정 매개변수가 될 수 있으며, End-to-End 학습 중에도 학습되므로 주 네트워크의 계층 내 및 계층 간 가중치 공유를 근사할 수 있습니다. 또한 우리의 임베딩 벡터는 하이퍼네트워크에 의해 동적으로 생성될 수도 있으므로, 순환 네트워크의 가중치가 시간 단계에 따라 변경되고 입력 시퀀스에 적응할 수 있습니다.
우리는 다양한 맥락에서 하이퍼네트워크의 동작을 조사하기 위해 실험을 수행하고, 하이퍼네트워크가 배치 정규화 및 계층 정규화와 같은 다른 기술과 잘 혼합된다는 것을 발견했습니다.
주요 결과는 하이퍼네트워크가 LSTM을 위한 비공유 가중치를 생성할 수 있으며, 이것이 표준 LSTM 버전(Hochreiter & Schmidhuber, 1997)보다 더 잘 작동한다는 것입니다.
Character Penn Treebank, Hutter Prize Wikipedia 데이터세트를 사용한 언어 모델링 작업에서 LSTM을 위한 하이퍼네트워크는 최첨단에 가까운 결과를 달성합니다.
IAM 필기 데이터세트를 사용한 필기 생성 작업에서 LSTM을 위한 하이퍼네트워크는 높은 정량적 및 정성적 결과를 달성합니다.
CIFAR-10을 사용한 이미지 분류에서 하이퍼네트워크가 깊은 합성곱 신경망(LeCun 외, 1990)의 가중치를 생성하는 데 사용될 때, 더 적은 학습 가능한 매개변수를 가지면서도 최첨단 모델과 비교하여 존경할만한 결과를 얻습니다.
단순한 작업 외에도, 우리는 LSTM을 위한 하이퍼네트워크가 대규모의 프로덕션 수준의 신경 기계 번역 모델의 성능 증가를 제공한다는 것을 보여줍니다.
Paper Appendix
논문의 실제 Appendix를 위한 공간입니다. 다음 장인 My Appendix는 제가 공부하면서 정리한 Appendix입니다.
My Appendix 1
What is Evolutionary Computing?
Evolutionary Computing은 생물학적 진화 과정에서 영감을 받은 최적화 알고리즘의 한 분야입니다. 자연 선택, 유전, 돌연변이 같은 자연의 진화 메커니즘을 컴퓨터 상에서 모방하여 복잡한 문제를 해결하는 인공지능 및 소프트 컴퓨팅의 하위 분야입니다.
핵심 개념과 작동 원리
진화 연산은 개체군 기반(population-based) 탐색 방식을 사용합니다. 후보 솔루션들(개체)을 모집단으로 구성하고, 각 개체의 적합도(fitness)를 평가한 후, 우수한 개체를 선택하여 교배(crossover)와 돌연변이(mutation)를 통해 새로운 세대를 생성합니다. 이 과정을 반복하면서 점진적으로 더 나은 솔루션으로 진화해 나갑니다.
주요 구성 요소는 다음과 같습니다:
- 선택(Selection): 적합도가 높은 개체를 우선적으로 선택
- 교배(Crossover/Recombination): 부모 개체의 정보를 결합하여 자손 생성
- 돌연변이(Mutation): 무작위 변화를 도입하여 다양성 확보
- 적합도 함수(Fitness Function): 솔루션의 품질을 평가하는 기준
주요 알고리즘 종류
진화 연산은 여러 알고리즘 계열을 포함합니다:
- 유전 알고리즘(Genetic Algorithms, GA): 가장 널리 사용되는 방법
- 진화 전략(Evolution Strategies, ES): 실수형 최적화에 특화
- 진화 프로그래밍(Evolutionary Programming, EP): 유한 상태 기계 진화
- 유전 프로그래밍(Genetic Programming, GP): 프로그램 구조 자체를 진화
- 군집 지능(Swarm Intelligence): 개미 군집 최적화(ACO), 입자 군집 최적화(PSO) 등
연구 분야로서의 특징
진화 연산은 다음과 같은 특징으로 인해 광범위하게 활용됩니다:
- 전역 최적화: 지역 최적점(local optima)에 덜 빠지고 전역 해를 찾을 수 있음
- 문제 독립성: 문제에 대한 사전 가정이 거의 필요 없음
- 병렬화 가능성: 개체군 기반 특성으로 대규모 병렬 처리에 적합
- 복잡한 문제 해결: 방대한 해공간과 비선형성을 가진 문제에 효과적
기계학습과의 결합
진화 연산은 기계학습, 특히 신경망 분야와 깊이 결합되고 있습니다:
- 신경망 구조 탐색(Neural Architecture Search, NAS): 최적의 신경망 구조를 자동으로 설계
- 뉴로진화(Neuroevolution): 신경망의 가중치, 구조, 하이퍼파라미터를 진화
- AutoML: 기계학습 모델과 파이프라인을 자동으로 최적화
최신 연구 동향 (2024-2025)
1. 뉴로진화와 신경망 최적화
대규모 심층 신경망 최적화가 주요 연구 주제입니다. 2024-2025년 연구들은 진화 알고리즘을 사용하여 심층 신경망의 구조와 하이퍼파라미터를 최적화하는 방법을 탐구하고 있습니다.
“Evolving Neural Architectures: A Genetic Algorithm Approach to Deep Learning Optimization” (2024): 유전 알고리즘을 사용한 신경망 구조 최적화 연구로, 적응적 개체군 제어, 다양성 보존 돌연변이, 하이브리드 강화학습 전략을 제안했습니다. 병렬 처리와 가중치 공유를 통해 계산 부담을 줄이는 생물학적 영감 접근법을 도입했습니다.
GECCO 2025 - Neuroevolution at Work Workshop: 2025년 주요 학회에서는 뉴로진화와 NAS의 통합이 핵심 주제입니다. 파라미터 공간 다양성 부족 문제와 계산 효율성 향상이 주요 도전 과제로 제기되고 있습니다.
2. GPU 가속 진화 알고리즘
텐서화(Tensorization)를 활용한 GPU 가속이 중요한 트렌드입니다:
- “GPU-accelerated Evolutionary Multiobjective Optimization Using Tensorized RVEA” (GECCO 2024): GPU를 활용한 대규모 다목적 최적화
- “Tensorized NeuroEvolution of Augmenting Topologies for GPU Acceleration” (GECCO 2024): NEAT 알고리즘의 GPU 가속 버전
- “Tensorized Ant Colony Optimization for GPU Acceleration” (GECCO 2024): 개미 군집 최적화의 GPU 병렬화
3. 협력적 공진화(Cooperative Co-evolution)
고차원 문제 해결을 위한 협력적 공진화 연구가 활발합니다:[8]
- “PyCCEA: A Python package of cooperative co-evolutionary algorithms for feature selection” (2025): 고차원 특징 선택 문제를 위한 협력적 공진화 프레임워크를 제공합니다. 문제를 여러 하위 구성요소로 분할하여 각각 독립적으로 진화시키는 방식입니다.
4. 진화와 학습의 시너지
진화와 학습의 결합이 주목받고 있습니다:
“Neuroevolution insights into biological neural computation” (Science, 2025년 2월): 진화가 신경 회로 구조를 어떻게 형성하는지, 그리고 진화와 학습이 어떻게 협력하는지에 대한 종합적 리뷰. 진화는 신경망 구조를 최적화하고, 학습은 개체가 생애 동안 적응할 수 있게 합니다.
연구 결과에 따르면, 진화된 신경망은 모듈성(modularity), 전문화된 제어 메커니즘(command neurons), 효율적 학습을 위한 구조적 특성을 자연스럽게 발달시킵니다.
5. 분산 진화 신경망
빅데이터를 위한 분산 처리 프레임워크가 발전하고 있습니다:
- “A novel neural network model with distributed evolutionary algorithm” (Nature, 2023): Apache Spark 프레임워크를 사용한 분산 유전 알고리즘 기반 신경망 학습. 대용량 데이터에서 전통적 방법 대비 80% 이상의 계산 시간 개선을 달성했습니다.
6. 최신 응용 분야
2024-2025년 연구들은 다양한 실제 응용에 진화 연산을 적용하고 있습니다:
- 재료 과학: Neuroevolution Potential (NEP) 접근법이 분자 동역학 시뮬레이션에서 탁월한 정확도와 계산 효율성을 보이고 있습니다.
- 음악 분류: 차등 진화 알고리즘을 사용한 CNN 파라미터 최적화
- 의료 진단: 암 스크리닝을 위한 앙상블 자연 영감 알고리즘
- 로봇공학: 자가 조직화 입자 시스템의 집단 행동 진화
- 공기역학: 심층학습과 유전 알고리즘을 결합한 공기역학적 설계
7. 주요 학술 컨퍼런스 및 저널
진화 연산 분야의 최신 연구는 다음 학술 장소에서 발표됩니다:
- GECCO (Genetic and Evolutionary Computation Conference): 가장 권위 있는 학회
- Evolutionary Computation (MIT Press): 최고 수준의 저널
- Swarm and Evolutionary Computation: 전문 저널
- Nature, Science: 최근 뉴로진화 관련 리뷰 논문 게재
진화 연산은 생물학적 원리를 컴퓨터 과학에 적용하여 복잡한 최적화 문제를 해결하는 강력한 도구로, 현재 인공지능, 특히 신경망 설계와 최적화 분야에서 혁신적인 돌파구를 제공하고 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
My Appendix 2
HyperNetworks와 Bayesian Meta-Learning, Uncertainty의 결합
1. HyperNetworks의 Bayesian 결합 가능 요소
1.1 가중치 생성 메커니즘의 확률적 해석
HyperNetworks의 핵심 구조가 Bayesian 프레임워크와 자연스럽게 결합됩니다:[1][2]
논문에서 하이퍼네트워크는 임베딩 벡터 \[z\]를 받아 가중치 \[W\]를 생성합니다. 이를 Bayesian 관점에서 재해석하면:[3]
- Point estimate (원논문): \[W = f_{\theta}(z)\]
- Bayesian 확장: \[W \sim p(W|z, \theta)\]로 가중치의 사후 분포(posterior distribution)를 모델링[2][1][4]
장점: - 태스크별 가중치의 불확실성을 명시적으로 모델링 - 데이터가 적은 few-shot 상황에서 epistemic uncertainty 포착[2][1]
1.2 동적 임베딩의 불확실성
논문의 동적 하이퍼네트워크는 입력에 따라 임베딩이 변하는데, 이는 Bayesian 관점에서 매우 풍부한 연구 주제입니다:[5][3]
- 임베딩 자체에 불확실성 부여: \[z \sim p(z|\text{task})\][6][5]
- Bayesian meta-prompt 개념과 연결[5]
- 태스크 표현의 불확실성이 가중치 불확실성으로 전파[4][7]
1.3 계층별 가중치 스케일링
논문의 weight scaling vectors 접근법:[3]
W(d(z)) = W ⊙ d(z)이는 Bayesian 관점에서: - \[d(z)\]를 확률 변수로 확장 가능 - 전체 가중치 행렬보다 낮은 차원에서 불확실성 모델링 - 계산 효율적인 Variational Inference 가능[1][2]
2. 최신 연구: BayesianHMAML (2022)
Hypernetwork approach to Bayesian MAML이 대표적인 사례입니다.[2][1]
2.1 핵심 아이디어
기존 MAML의 한계: - 그래디언트 기반 업데이트만 사용 - 불확실성 정량화 불가 - Few-shot 상황에서 과적합 위험[1][2]
BayesianHMAML의 해결책:[2][1]
(μ(Si), σ(Si)) = Hφ(Si, fθ(Si))
θ'i ~ N(θ + μ(Si), σ(Si))하이퍼네트워크 \[H_{\phi}\]가: - 서포트 세트 \[S_i\]로부터 정보 집계 - 태스크별 가중치의 평균(μ)과 분산(σ) 생성[1][2] - 가중치를 분포에서 샘플링하여 불확실성 포착[2][1]
Decision Making 관점의 장점:[8][2] - Epistemic uncertainty 정량화: 모델이 얼마나 확신하는지 측정 - Rejection diagnosis: 불확실성이 높은 예측은 거부 가능[7] - Risk-aware decision: 불확실성을 고려한 안전한 의사결정[9]
2.2 실험 결과
BayesianHMAML은 다음에서 우수한 성능을 보였습니다:[8][2] - miniImageNet 5-way 1-shot: 기존 MAML 대비 정확도 향상 - Uncertainty calibration: 예측 불확실성이 실제 오류와 높은 상관관계 - Out-of-distribution detection: OOD 샘플 탐지 능력 향상[8]
3. 최신 연구 트렌드 (2024-2025)
3.1 Meta-Mol: 약물 발견을 위한 Bayesian Meta-Learning
“Pushing the boundaries of few-shot learning for low-data drug discovery” (Nature Communications, 2025):[4]
문제 상황: - 약물 특성 예측은 데이터 부족 문제 심각 - 잘못된 예측은 임상 시험 실패로 이어짐 - Uncertainty 정량화 필수[4]
Meta-Mol의 접근법:[4] 1. Bayesian MAML 변형: 범용 가중치(universal weights)는 point estimate, 태스크별 가중치는 사후 분포로 학습 2. HyperNetwork 활용: 서포트 세트에서 사후 분포의 파라미터(평균, 분산) 직접 생성[4] 3. 복잡한 사후 분포 학습: 충분히 표현력 있는 하이퍼네트워크로 임의의 사후 분포 근사[4]
Decision Making에의 기여:[4] - 불확실성 기반 샘플 필터링: 신뢰도 낮은 예측 제거 - 리스크 인지 약물 설계: 부작용 가능성이 높은 화합물 사전 제외 - 능동 학습(Active Learning): 불확실성이 높은 영역에 실험 자원 집중
3.2 UBMF: 결함 진단을 위한 Uncertainty-aware Bayesian Meta-Learning
“UBMF: Uncertainty-aware bayesian meta-learning framework” (2025):[7]
산업 응용에서의 Uncertainty:[7] - 3가지 불확실성 원천: 미지의 조건, 적은 샘플, 도메인 외 데이터 - 잘못된 진단은 장비 파손이나 안전 사고로 이어질 수 있음[7]
핵심 기여:[7] 1. 통합 불확실성 모델링: Aleatoric과 epistemic uncertainty를 체계적으로 구분하고 정량화[7] 2. 불확실성 기반 샘플 필터링: OOD 샘플을 자동으로 감지하고 제거[7] 3. Bayesian 메타 지식 추출: 사후 확률 보정으로 분류기 정밀도 향상[7]
Decision Making 프레임워크:[7] - 신뢰도 임계값 설정: 불확실성이 높으면 인간 전문가에게 판단 위임 - 리스크 기반 우선순위: 고위험 결함을 우선 처리 - 적응적 진단: 새로운 조건에서 메타 지식을 활용하여 빠르게 적응
3.3 Trust-Bayes: 신뢰할 수 있는 Uncertainty Quantification
“Bayesian meta learning for trustworthy uncertainty quantification” (2024):[10][11]
문제 정의:[10] - 기존 Bayesian 방법들은 모델 불확실성과 데이터 불확실성을 혼동 - 부정확한 불확실성 추정은 잘못된 의사결정으로 이어짐[10]
Trust-Bayes 프레임워크:[10] - Trustworthy uncertainty: 보정된(calibrated) 불확실성 제공 - Meta-learning과 결합: 다양한 태스크에서 학습하여 일반화 가능한 불확실성 추정 - 최적화 프레임워크: 불확실성 품질을 명시적으로 최적화[10]
3.4 SurvUnc: 생존 분석을 위한 Meta-Model 기반 Uncertainty
“SurvUnc: A Meta-Model Based Uncertainty Quantification Framework” (2024):[12][13]
의료 의사결정에서의 중요성:[12] - 생존 예측의 불확실성은 치료 결정에 직접적 영향 - 높은 불확실성 → 추가 검사 필요 - 낮은 불확실성 → 적극적 치료 가능[12]
메타 모델 접근법:[13][12] - Base survival model 위에 경량 메타 모델 구축 - Anchor-based learning: Concordance 개념을 활용한 불확실성 학습[12] - Post-hoc uncertainty: 기존 모델 수정 없이 불확실성 추가[12]
평가 프로토콜:[12] - Selective prediction: 확신도 높은 예측만 사용 - Misprediction detection: 오류 가능성 사전 파악 - OOD detection: 분포 외 환자 식별[12]
4. Decision Making에서 Uncertainty의 역할
4.1 Exploration-Exploitation Trade-off
Meta-RL에서의 불확실성 활용:[14][15][9]
Risk-aware Meta-level Decision Making (2022):[9] - 로봇 탐사에서 epistemic uncertainty로 탐사 전략 결정 - 불확실성 높은 영역 → 탐사 가치 높음 - 불확실성 낮은 영역 → 활용(exploitation) 전략[9]
Meta-reinforcement learning for quantum control (Nature, 2025):[14] - 양자 시스템의 불확실성 존재 하 제어 - 메타 학습으로 환경 변화에 강건한 제어 - 내부 루프(specific task)와 외부 루프(meta-learning) 이중 구조[14]
Grasp Learning with Uncertainty (2018):[15] - Epistemic uncertainty: 지식 부족으로 인한 불확실성 → 탐사로 감소 가능 - Aleatoric uncertainty: 데이터 노이즈 → 탐사로 감소 불가 - Epistemic만 활용한 탐사가 훨씬 효과적[15]
4.2 Uncertainty의 두 가지 유형과 의사결정
Epistemic Uncertainty (인식론적 불확실성):[16][15][12][7] - 원인: 모델의 지식 부족, 학습 데이터 부족 - 특징: 추가 데이터로 감소 가능 - Decision making: - 높은 epistemic uncertainty → 더 많은 데이터 수집 필요[15] - Active learning의 샘플 선택 기준[15] - 탐사(exploration) 전략에 활용[16][9]
Aleatoric Uncertainty (우연적 불확실성):[15][12][7] - 원인: 데이터 자체의 노이즈, 측정 오류 - 특징: 더 많은 데이터로도 감소 불가 - Decision making: - 높은 aleatoric uncertainty → 본질적으로 예측 어려운 케이스 - 리스크 관리: 보수적 결정 필요[7] - 예측 거부(rejection) 고려[7]
4.3 Uncertainty-guided Meta-Learning
UAPML: Uncertainty-Aware Prompted Meta-Learning (2024):[5]
핵심 아이디어:[5] - Bayesian meta-prompt: 메타 프롬프트 자체에 불확실성 부여 - 사후 불확실성이 태스크별 프롬프트 불확실성과 일치함을 이론적으로 증명[5] - Hard vs Soft 방식: 불확실성에 따라 자동으로 프롬프트 구성 방식 선택[5]
계산 효율성:[5] - 모델 백본 고정, 프롬프트만 조정 - 전체 가중치 업데이트 대비 80% 이상 계산 비용 감소 - 성능 저하 없이 빠른 적응[5]
5. HyperNetworks 논문에 Bayesian을 적용할 구체적 방법
5.1 정적 하이퍼네트워크의 Bayesian 확장
원논문의 접근:[3]
z_i: fixed layer embedding (learnable parameter)
W_i = f_θ(z_i)Bayesian 확장 방안:
z_i ~ N(μ_z, Σ_z): 임베딩의 사후 분포
W_i = f_θ(z_i): 가중치 생성
p(W_i | data) = ∫ p(W_i | z_i) p(z_i | data) dz_i구현 방법:[1][2] - Variational Inference로 \[q(z_i)\] 학습 - Reparameterization trick: \[z_i = \mu_z + \sigma_z \odot \epsilon\], where \[\epsilon \sim N(0,1)\] - 여러 샘플로 앙상블 예측[2]
5.2 동적 하이퍼네트워크의 Bayesian 확장
원논문의 동적 임베딩:[3] - LSTM의 hidden state가 시간에 따라 변하며 가중치 생성 - 입력 시퀀스에 적응적
Bayesian 해석:[2][4]
h_t: LSTM hidden state at time t
z_t = g(h_t): dynamic embedding
(μ_W(t), σ_W(t)) = Hypernetwork(z_t)
W_t ~ N(μ_W(t), diag(σ_W(t)^2))Uncertainty 전파: - 시간에 따른 epistemic uncertainty 변화 추적 - 초반에는 높은 불확실성, 더 많은 정보 관찰 시 감소 - Decision making: 불확실성 임계값 이하일 때만 예측 출력[12][7]
5.3 Layer Normalization과 Bayesian의 결합
논문에서 Layer Norm + HyperLSTM이 효과적임을 보였습니다.[3]
Bayesian 관점의 해석:[17] - Layer Normalization은 암묵적 정규화 효과 - Bayesian 프레임워크와 결합 시 사후 분포의 분산 안정화[17] - 불확실성 추정의 품질 향상[17]
6. 실용적 구현 전략
6.1 경량 Bayesian HyperNetworks
문제: Full Bayesian inference는 계산 비용이 높음[2][4]
해결책:[2][4] 1. Universal weights는 point estimate: 공통 지식은 deterministic 2. Task-specific weights만 Bayesian: 불확실성이 중요한 부분만 3. Low-rank approximation: \[\Sigma = LL^T\]로 분산 행렬 저차원화[2]
6.2 Ensemble 기반 접근
Deep Ensemble과 HyperNetworks 결합:[18][15]
# Multiple hypernetworks
hypernetworks = [HyperNet() for _ in range(N)]
# Generate ensemble predictions
predictions = []
for hyper in hypernetworks:
W = hyper.generate_weights(task_embedding)
pred = main_network(input, W)
predictions.append(pred)
# Uncertainty estimation
mean_pred = mean(predictions)
epistemic_unc = variance(predictions)장점:[18] - 구현 간단 - 병렬화 용이 - Gradient 기반 학습 가능
6.3 MC Dropout with HyperNetworks
Variational inference의 근사:[17]
# Enable dropout during inference
hypernetwork.train() # Keep dropout active
predictions = []
for _ in range(K): # K samples
W = hypernetwork(task_embedding)
pred = main_network(input, W)
predictions.append(pred)
uncertainty = std(predictions)계산 효율성:[17] - 단일 모델만 필요 - Inference 시 multiple forward pass - 추가 학습 비용 없음
7. 향후 연구 방향과 제안
7.1 HyperNetworks + Bayesian + Meta-Learning 통합
제안하는 프레임워크:
- Outer loop (Meta-learning):
- 다양한 태스크에서 하이퍼네트워크 파라미터 학습
- 태스크 분포 \[p(T)\]에서 샘플링[19][2]
- Middle loop (HyperNetwork):
- 태스크 임베딩에서 가중치 분포 생성[1][2]
- \[(μ_W, σ_W) = H_φ(z_{\text{task}})\]
- Inner loop (Bayesian Inference):
- 소수의 샘플로 빠른 적응[1][2]
- Uncertainty 정량화로 예측 신뢰도 제공[12][7]
7.2 Decision Making 응용 시나리오
금융 의사결정: - 시장 변화 → 새로운 태스크 - HyperNetwork로 빠르게 새 전략 생성 - Uncertainty로 리스크 관리 - 불확실성 높은 시기 → 보수적 포트폴리오
자율주행: - 다양한 날씨/도로 조건 → 태스크 - Meta-learning으로 새 조건 빠른 적응 - Epistemic uncertainty로 탐사 영역 결정 - 높은 불확실성 → 인간에게 제어 이양[9]
의료 진단:[4] - 환자 특성 → 태스크 - Few-shot으로 희귀 질환 진단 - Uncertainty로 추가 검사 필요성 판단 - Aleatoric uncertainty 높음 → 예측 불가능, 경과 관찰
결론
HyperNetworks 논문은 Bayesian 프레임워크와 결합할 수 있는 풍부한 요소들을 가지고 있습니다:
주요 결합 요소: - 가중치 생성 메커니즘 → 확률 분포로 확장 - 임베딩 벡터 → 불확실성 부여 - 동적 가중치 → 시간에 따른 불확실성 변화
최신 연구 현황: - BayesianHMAML (2022): Few-shot learning + uncertainty[1][2] - Meta-Mol (2025): 약물 발견 + Bayesian hypernetwork[4] - UBMF (2025): 결함 진단 + uncertainty-aware meta-learning[7] - SurvUnc (2024): 생존 분석 + meta-model uncertainty[12]
Decision Making에의 기여: - Epistemic uncertainty: 탐사 전략, active learning[16][9][15] - Aleatoric uncertainty: 리스크 관리, 예측 거부[7] - Calibrated uncertainty: 신뢰할 수 있는 의사결정[11][10]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40